
The News: Ollama Learns a New Language
Claude Code can now talk to your locally-hosted models without any extra adapters, proxies, or dark magic.
"Ollama v0.14.0 and later are now compatible with the Anthropic Messages API, making it possible to use tools like Claude Code with open-source models." — Ollama Blog
Cue the excitement: Finally! Unlimited coding on steroids! No more watching your token budget evaporate! 24/7 AI-assisted development without the API bill anxiety!
...right?
Why Test This, You Ask?
Naturally, I had to try this immediately. What better excuse to fire up the DGX Spark and see what these local models can really do?
If you're running a DGX Spark (or any beefy GPU setup), this means you can now fire up Claude Code and have it talk to whatever model you've got running locally. Zero cloud dependency. Zero API costs eating into your coffee budget. Just pure, local AI goodness.
But does it actually work? Let's find out.
Setting It Up
Which Model?
The official docs recommend a few options:
Cloud models (if you're into that sort of thing):
glm-4.7:cloud,minimax-m2.1:cloud,qwen3-coder:480b
Local models (the fun part):
qwen3-coder- Excellent for coding tasksgpt-oss:20b- Strong general-purpose modelglm-4.7-flash- Deep reasoning, needs Ollama 0.14.3
I tested several of these locally - qwen3-coder is genuinely impressive for coding tasks, and glm-4.7-flash (just released with Ollama 0.14.3) surprised me with its deep reasoning approach. Cloud models? Kind of defeats the purpose of running local, doesn't it?
Bump Ollama's Context Window
The docs recommend at least 32k context. Use systemctl edit for a persistent override that survives updates:
Add this in the editor that opens:
[Service]
"OLLAMA_CONTEXT_LENGTH=32000"
"OLLAMA_FLASH_ATTENTION=1"
"OLLAMA_KV_CACHE_TYPE=f16"
Bonus performance tweaks:
OLLAMA_FLASH_ATTENTION=1- Normal attention loads the entire context into memory at once. Flash Attention breaks it into chunks, processes them sequentially, and combines the results. Same output, way less memory.OLLAMA_KV_CACHE_TYPE=f16- Keeps the K/V cache at full precision (default). Useq8_0to halve memory if you're tight on VRAM.
How much context can you actually fit? The VRAM Calculator is your friend. Play around with your model size, quantization, and available VRAM - it'll tell you the exact settings to max out each model.
Then restart:
PowerShell Helper for Your Work Machine
This little function lives in my $PROFILE:
Now I just type Enter-ClaudeSpark and Claude Code magically routes everything to my DGX Spark. The ANTHROPIC_AUTH_TOKEN is set to ollama because Ollama doesn't actually need a real token - it just checks if the header exists. Clever.
My Test: Meeting Destruction Therapy
Public benchmarks are meaningless. Every new model release beats the last one. Numbers go up, leaderboards shuffle, and somehow everyone's the best at everything. But as an end user, what actually matters is how it feels - how well an LLM adapts to your language and understands what you're asking for. So I built my own benchmark. A fun one.
I needed something creative, visual, and complex enough to separate the wheat from the chaff. What better way than asking these models to build a Breakout-style game where you "reschedule" your weekly meetings by smashing them with a paddle?
The Prompt:
- ---
- - - - --- - - -
- ----
- ---
- --
-
I threw this at several models through Claude Code and timed the results:
| Model | Time | Rating |
|---|---|---|
| Claude Opus 4.5 | 2m 30s | ⭐⭐⭐⭐⭐ |
qwen3-coder:30b | 1m 48s | ⭐⭐⭐⭐ |
gpt-oss:20b | 4m 24s | ⭐⭐⭐ |
glm-4.7-flash | 8m 45s | ⭐⭐⭐ |
nemotron-3-nano:30b | 2m 46s | ⭐ |
ministral-3:14b | - | 🚩 |
rnj-1 | - | 🚩 |
Claude Opus 4.5 (Reference)
Not self-hosted - this is the cloud-based frontline model, included for comparison. Understood the creative brief, nailed the game mechanics, produced clean and maintainable code. No surprises there.
qwen3-coder:30b
Faster than expected, and it actually produced something playable. At 30B parameters, genuinely impressive.
gpt-oss:20b
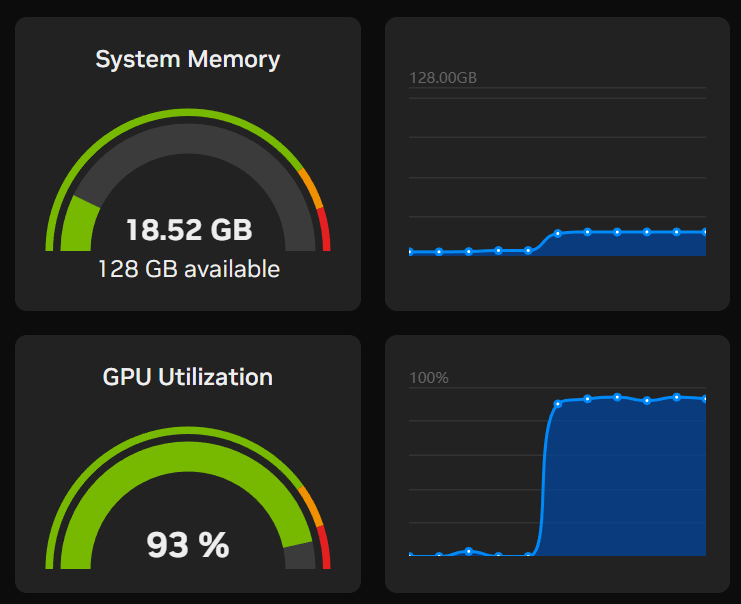
For this one I went all out - maxed context window at 95k with full precision KV cache:
"OLLAMA_CONTEXT_LENGTH=95232"
"OLLAMA_FLASH_ATTENTION=1"
"OLLAMA_KV_CACHE_TYPE=f16"
Solid result! The 20B variant delivered a working game with proper paddle controls. Not as polished as qwen3-coder, but definitely playable. A good middle-ground option if you want something from the GPT family.
glm-4.7-flash
"As the strongest model in the 30B class, GLM-4.7-Flash offers a new option for lightweight deployment that balances performance and efficiency." - Bold claims require testing. This one needs Ollama 0.14.3 (just released!).
Why the 8+ minute runtime? GLM spends serious time in its thinking stage. Watch the Ollama output live and you'll see deep, methodical reasoning - no "what if" self-doubt loops, just clear and consistent problem-solving. The result shows: best physics of all the OSS models I tested. The ball movement felt smooth and responsive. The catch? It completely ignored the meeting-themed UI brief and went with a generic breakout style instead. So close, yet so far.
nemotron-3-nano:30b
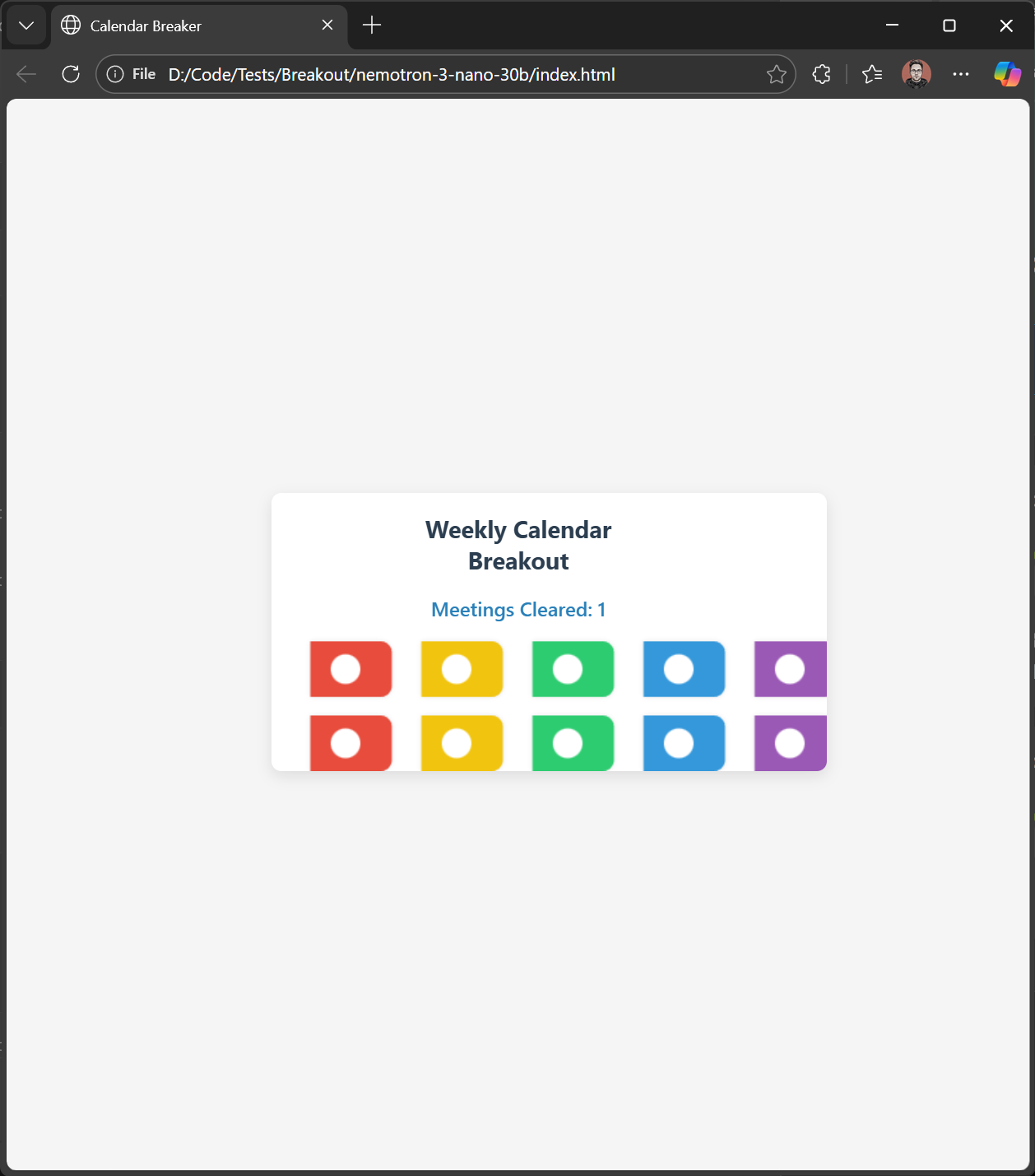
It rendered something! Got the calendar theme, colorful meeting blocks, even a "Meetings Cleared" counter. But... where's the ball? Where's the paddle? Apparently Nemotron thought breakout meant "break out of implementing game mechanics." Nice UI though.
This one makes me a bit sad, honestly. NVIDIA has been releasing incredible AI stuff lately - the voice models alone are mind-blowing - but Nemotron-3-Nano just flopped here. Maybe it shines elsewhere, but for Claude Code workflows? Not ready.
ministral-3:14b
I really tried with this one. Multiple attempts, different prompts, fresh sessions. Every single time: Claude Code just... completed. Immediately. No files, no code, no output. It's like the model and Claude Code looked at each other and mutually agreed to do nothing. 🤷
rnj-1
"8B parameter open-weight, dense models trained from scratch by Essential AI, optimized for code and STEM with capabilities on par with SOTA open-weight models." - 130k downloads, fresh release, sounded promising. The VSCode + Cline demo on their blog looked great - but that was a Python game, not our HTML/JS breakout challenge.
Unfortunately, no results here. Another one that just didn't produce anything usable with Claude Code. At least the resource usage was... well, not surprising for an 8B model.
Wrapping Up
So, Ollama now speaks the Messages API, and Claude Code can talk to local models. I put it through a fun benchmark - building a calendar breakout game - and the results were clear: Opus still delivers the goods, but the OSS models are catching up fast.
For Claude Code agentic workflows, qwen3-coder is the clear winner in the OSS space - fast, capable, and actually follows instructions. glm-4.7-flash has potential but needs work on following prompts. gpt-oss:20b is a solid middle-ground option.
This actually reflects my broader model philosophy: ChatGPT-style models for basic tasks - rephrasing, docs, research. Anthropic for serious coding work. And now in the open-source world, qwen3-coder is genuinely fun to work with.
Is this going to replace Claude Opus for serious work? Not today. But for experimentation, learning, and those times when you want to see what the open-source world can do? This setup is fantastic.
What's Next?
Want to try this yourself?
- Install Ollama ≥ 0.14:
curl -L https://ollama.com/install.sh | sh - Pull your model of choice:
ollama pull qwen3-coder:30b - Bump the context window to at least 32k
- Add the PowerShell helper to your
$PROFILE - Fire up Claude Code and start breaking some meetings... I mean, coding
And who knows - at the rate these models are improving, maybe in a few months I'll have to eat my words about frontline models being irreplaceable.
In the meantime, building a game that lets you destroy your weekly meetings with a bouncing ball might be the most satisfying thing I've prompted this month.
Happy hacking! 🎮